When working with flat files, encoding needs to be factored in right away to avoid issues down the line. UTF-8 (or UTF-16) is the de facto encoding that you hope to get. If the encoding is different, pay attention on how you load the file into R.
Let’s take the example of a file encoded as Windows-1252. Its content is displayed below using Notepad++. The editor does a pretty good job figuring out the encoding of the file. The encoding is displayed in the status bar while the Encoding menu enables you to change the selected character set.
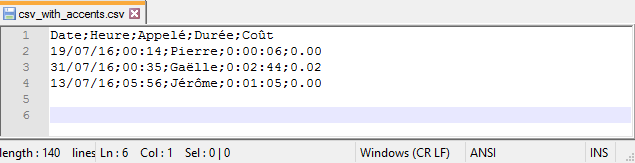
Beware of the default encoding
I work on Windows, and the Windows-1252 encoding is native to the platform:
Sys.info()['sysname']## sysname
## "Windows"Sys.getlocale()## [1] "LC_COLLATE=English_United States.1252;LC_CTYPE=English_United States.1252;LC_MONETARY=English_United States.1252;LC_NUMERIC=C;LC_TIME=English_United States.1252"Loading the CSV file from Windows with the utils package appears to be a breeze:
utils::read.csv2(file = file_path)## Date Heure Appelé Durée Coût
## 1 19/07/16 00:14 Pierre 0:00:06 0.00
## 2 31/07/16 00:35 Gaëlle 0:02:44 0.02
## 3 13/07/16 05:56 Jérôme 0:01:05 0.00However, once moving the code onto a Linux-environment, I got the following error:
Error in make.names(col.names, unique = TRUE) :
invalid multibyte string 3
On Linux environments, the locale is usually UTF-8:
Sys.getlocale()[1] "LC_CTYPE=fr_FR.UTF-8;LC_NUMERIC=C;LC_TIME=C.UTF-8;LC_COLLATE=C.UTF-8;LC_MONETARY=C.UTF-8;LC_MESSAGES=C.UTF-8;LC_PAPER=fr_FR.UTF-8;LC_NAME=C;LC_ADDRESS=C;LC_TELEPHONE=C;LC_MEASUREMENT=fr_FR.UTF-8;LC_IDENTIFICATION=C"
The file encoding needs therefore to be explicit as to ensure portability:
utils::read.csv2(file = file_path, fileEncoding = 'WINDOWS-1252')Note that the following code is equivalent:
utils::read.csv2(file = file(file_path, encoding = 'WINDOWS-1252'))read.csv2 uses by default the native encoding to load the CSV file.
getOption('encoding')## [1] "native.enc"If the default encoding varies from plateform to plateform, your code may not work unless you specify the type of encoding you want to have. For reproducible results, you may also want to refine the encoding used by default in our R session.
What about the readr package?
The readr package is becoming a favorite among the R community. By default, UFT-8 encoding is assumed (see readr::default_locale()), leading to issues:
readr::read_csv2(file = file_path)## Using ',' as decimal and '.' as grouping mark. Use read_delim() for more control.## Parsed with column specification:
## cols(
## Date = col_character(),
## Heure = col_time(format = ""),
## `Appel<e9>` = col_character(),
## `Dur<e9>e` = col_time(format = ""),
## `Co<fb>t` = col_character()
## )## # A tibble: 3 x 5
## Date Heure `Appel\xe9` `Dur\xe9e` `Co\xfbt`
## <chr> <time> <chr> <time> <chr>
## 1 19/07/16 00:14:00 Pierre 00:00:06 0.00
## 2 31/07/16 00:35:00 "Ga\xeblle" 00:02:44 0.02
## 3 13/07/16 05:56:00 "J\xe9r\xf4me" 00:01:05 0.00The locale is UTF-8 be default:
readr::default_locale()## <locale>
## Numbers: 123,456.78
## Formats: %AD / %AT
## Timezone: UTC
## Encoding: UTF-8
## <date_names>
## Days: Sunday (Sun), Monday (Mon), Tuesday (Tue), Wednesday (Wed),
## Thursday (Thu), Friday (Fri), Saturday (Sat)
## Months: January (Jan), February (Feb), March (Mar), April (Apr), May
## (May), June (Jun), July (Jul), August (Aug), September
## (Sep), October (Oct), November (Nov), December (Dec)
## AM/PM: AM/PMThe encoding needs to be specified using the locale parameter:
readr::read_csv2(file = file_path, locale = readr::locale(encoding = 'WINDOWS-1252'))## Using ',' as decimal and '.' as grouping mark. Use read_delim() for more control.## Parsed with column specification:
## cols(
## Date = col_character(),
## Heure = col_time(format = ""),
## Appelé = col_character(),
## Durée = col_time(format = ""),
## Coût = col_character()
## )## # A tibble: 3 x 5
## Date Heure Appelé Durée Coût
## <chr> <time> <chr> <time> <chr>
## 1 19/07/16 00:14:00 Pierre 00:00:06 0.00
## 2 31/07/16 00:35:00 Gaëlle 00:02:44 0.02
## 3 13/07/16 05:56:00 Jérôme 00:01:05 0.00Checklist
Let’s recap:
- Do you use encoding other than UTF?
- If so, does the file just contains plain ASCII characters? Does it contains extended ASCII characters (such as é, õ)? Does it contains non-extended characters such as Þ?
- Verify the encoding using external tools (such as Notepad++ if on Windows)
- Alternatively, use
guess_encoding:
readr::guess_encoding(file_path)## # A tibble: 2 x 2
## encoding confidence
## <chr> <dbl>
## 1 ISO-8859-1 0.52
## 2 ISO-8859-2 0.47- In which environment do you expect to run the code? Windows? Linux? What is the locale of theses systems?
- Check the locale
Sys.getlocale() - Check the supported encoding
iconvlist() - [Configure]((http://withr.me/configure-character-encoding-for-r-under-linux-and-windows/) character encoding if required.
- Check the locale
- Which package will you use to load the file?
-
readrvs.utils? - What is the default encoding used by these packages? (
getOption('encoding')vs.readr::default_locale())
-
- Finally, always specify the encoding being used to ensure greater portability of your code.